 Pricing
Support
Log in
Sign up
Pricing
Support
Log in
Sign up
by Almar Klein | published 03-02-2021 | last edited 25-02-2021
Importing your previous time-tracking data into TimeTagger
You can import your previous time-tracking records into TimeTagger using the import dialog.
Step 1: Obtain your data
First make sure that you have an export of your time tracking data, e.g. as a CSV file or in a spreadsheet program. Copy the data to the clipboard (select all and then select copy). Now move to step 2.
Step 2: Import your data into the sandbox
The sandbox is exactly like the TimeTagger app, except it does not sync with the server and forgets all the data once the tab is closed. This is a great environment to try out importing your data before you do it for real!
In the sandbox, go to the import dialog (via the menu), and paste your data into the text field (right-click and select paste). Then click analyse to process the data. The dialog will show it's progress, and will explain what went wrong if it did not understand the data. If the analysis was successful, you can hit import to finalize the import.
If everything looks fine, go to step 4. Otherwise go to step 3.
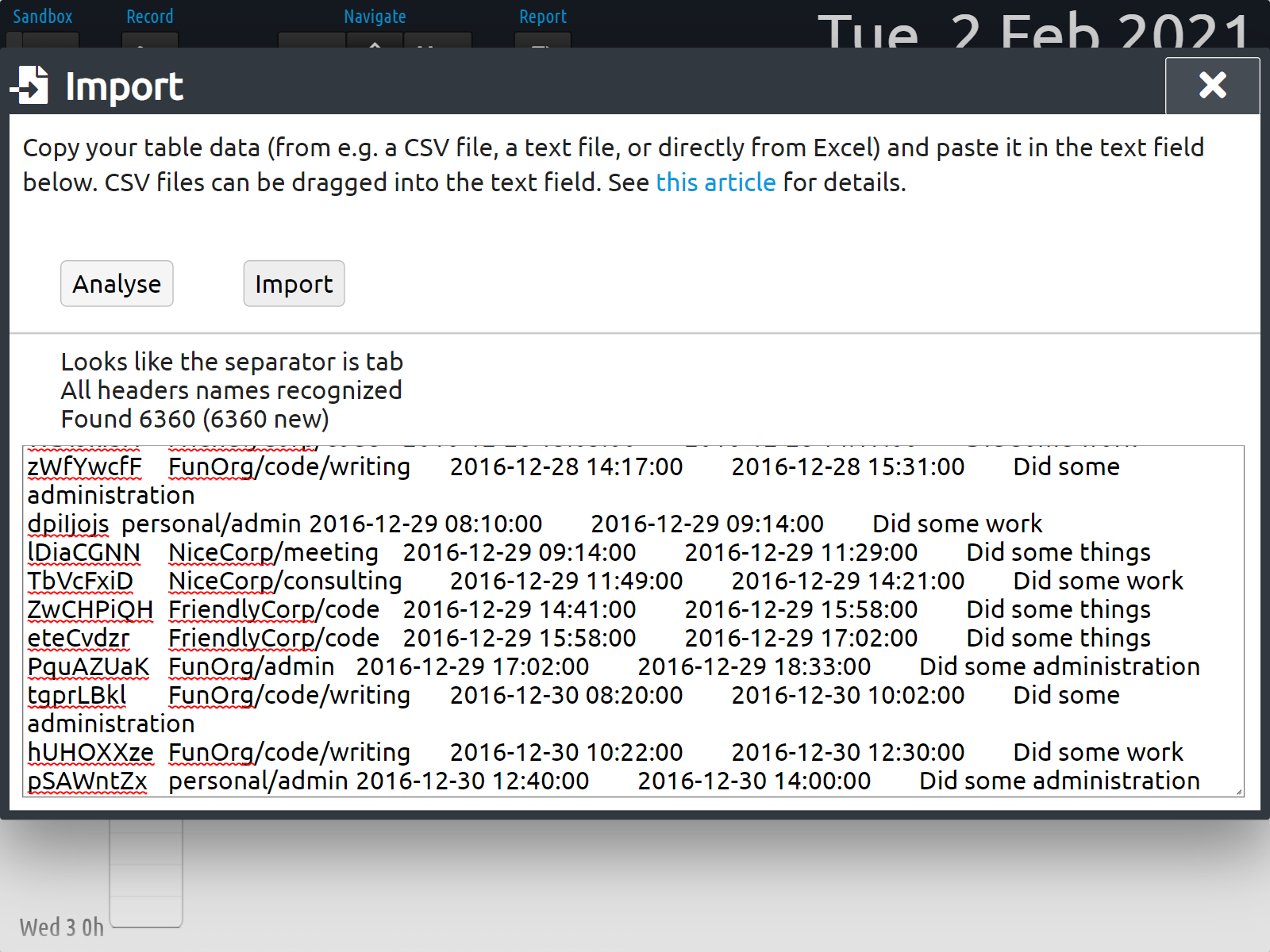
Step 3: In case your data needs work
If you're lucky, the TimeTagger import mechanism will just understand your data. This will be the case for data from TimeTurtle, Yast, TimeChimp, and possibly others. If this is not the case, you have two options:
- Try to fix the data by using the specification at the bottom of this post, then try step 2 again. If your data comes from a common time tracking solution, please let us know what you needed to do, so that the experience for other users can be improved!
- Ask for help and send us a small snippet of the data to import that can be used to make the import mechanism smarter.
Step 4: Import your data for real
Now repeat step 2, but in the actual app.
Step 5: Split tags (optional)
Any project names in your imported data have been converted into tags. If you were using some form of project structure (e.g. "client1/meeting"), you may want to split these into separate tags:
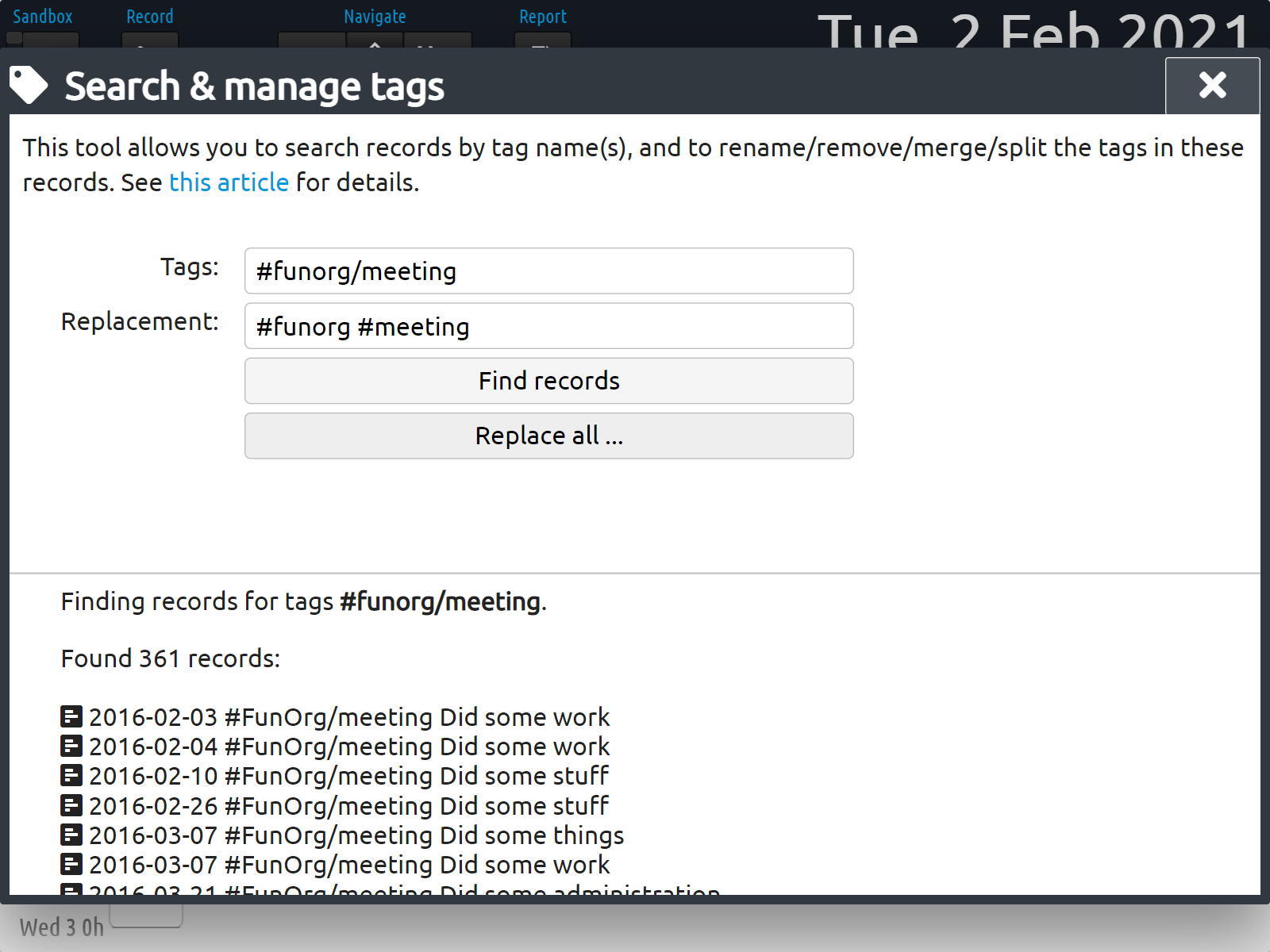
Have a look at the working with tags article to read more about how tags work.
Appendix: data import specification
The import data should consist of rows, where each row represents one record, and the top row is the header. Values on a row can be separated with either tab, comma, or semicolon (this is automatically detected). Wrapping values in double-quotes (as is common in CSV files) is supported.
The following headers are supported (aliases for each field are also accepted):
-
key (or id): existing records are replaced if they match the given key/id. If no key is provided, existing records are replaced if the start/stop times match.
-
tag (or tags/project): the tag or project name associated with the record.
-
start (or begin): a Unix timestamp or other date-time string (e.g. ISO 8601).
-
stop (or end): a Unix timestamp or other date-time string (e.g. ISO 8601).
-
description (or ds/comment/title/summary): a text, newlines and tabs are removed.
Each record should be resolvable into at least a start time and a stop time. Further, some formats specific to certain trackers are also supported. For instance:
- date: if given, the start time can also be in
hh:mmorhh:mm:ssformat. - duration: can be
hh:mm,hh:mm:ss, or simply the number of seconds. Is used when the stop time is not of the preferred format.